{kind=link}
Introduction
This post will walk through the process we followed to build a search engine for leaked credentials from publicly disclosed breaches/database leaks using Django REST Framework and PostgreSQL. At the end of this blog, you should have all you need to build an API and frontend Web Application that searches over 5 billion passwords in seconds. We'll include the relevant code snippets to follow along, as well as explanations and explorations of various options.
We'll walk through:
- Defining a database schema with Django's ORM
- How/Where to find leaks
- Writing a script to ingest userpass lists
- Deduping and adding unique constraints
- Exploring and Benchmarking PostgreSQL index options, including tutorials for setting up btree and trigram indices to support exact match search and regex/ilike searching of fields.
- Writing an API in Django REST Framework to search the database
In part 2 (Coming soon!) we'll cover putting this all together with building a frontend using the Angular Material Library and a complete sample code release.
Finished Product
At the end of this post you will end up with a working API to quickly search a database of billions of credentials.
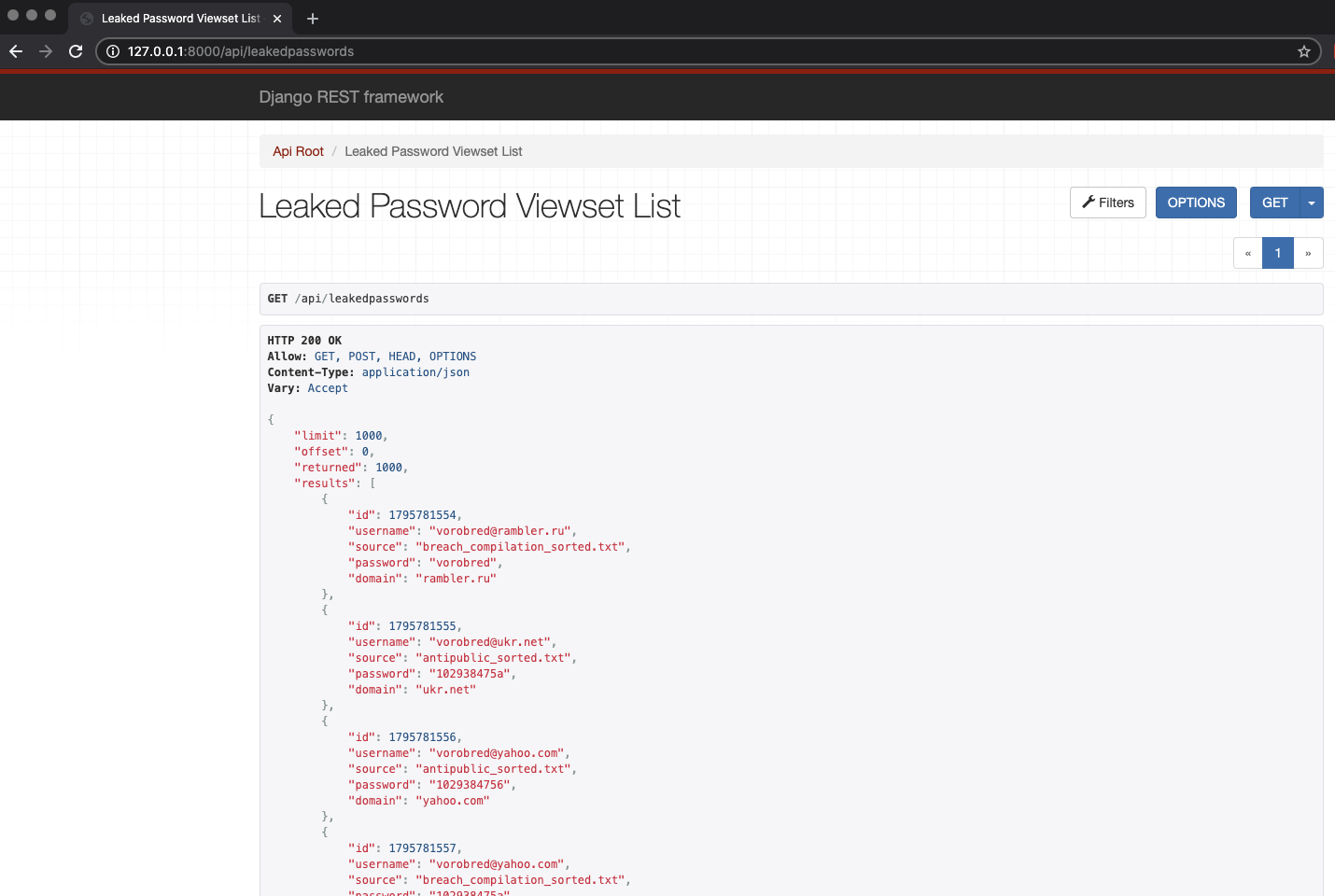
At the end of the series you should end up with something similar to the final result we built to use internally shown below:
Various code snippets will be provided throughout this post, and all snippets we are releasing in the series are under GPL2 licensing.
Note that this blog can't and won't cover everything you need to know about setting up PostgreSQL and Django. Get ready to dive in and do some reading on the linked documentation to fill in the gaps as you go along, it will be worth it :). If you'd rather just git clone a (mostly) working app, we've got you (mostly) covered in part 2.
Background
We've found these leaks to be a great initial source of email targets when password spraying a client's perimeter, as well as a useful add in to reporting. An OSINT appendix full of leaked credentials is much more exciting than just a list of emails after all. There are commercial services such as dehashed.org for this, but we found the DIY method much better as we can export, dump, and ingest as we need without relying on a third party or limited API calls. Have fun and use responsibly.
Defining the Database Schema
We will be using Django's ORM to initially define the schema of our data storage. You can also manually write the appropriate SQL statements, but creating models in Django maps well to our plan for using Django REST Framework as our API platform.
Setting up a Django App
Before diving into the schema, get Django stood up and ready to go. Follow this tutorial: https://www.djangoproject.com/start/. Create a django project, and then create a leakedpasswords app. You will then need to get PostgreSQL installed and connected up to Django: https://www.enterprisedb.com/postgres-tutorials/how-use-postgresql-django. Make sure to use PostgreSQL11
Defining the schema with Models.py
We opted for a simple single table schema which holds the password, the email, and the source file. For our needs, we really are just after emails and passwords and the source is not heavily used. We will also later be placing a unique together constraint on the email/password, so will be losing some data about where the sources came from.
If you are building a search engine more focused on documenting the source, it may be wise to have a source table instead that contains details on that source, with a foreign key relation on the email/password table linking to that source. This would allow for username and passwords that show up in multiple sources to not cause duplicate records as it would in our simple schema. Keep in mind, however, this may significantly slow ingestion times for large datasets, but queries should remain speedy.
Models.py
from django.db import models
class LeakedCredential(models.Model):
id = models.BigAutoField(primary_key=True, serialize=False, verbose_name='ID')
username = models.TextField()
source = models.TextField()
password = models.TextField()
domain = models.TextField(null=True, blank=True)
We define the following fields in our models.py above:
- username: In our case is actually just going to be storing an email address in most rows
- source: The name of the sourcefile
- password: The cleartext password
- domain: Just the domain of the email address. Although this information may already be captured in the username field itself, we parse the domain out and put in its own field so we can have a btree index on the domain, allowing extremely fast exact matches for a domain, which is our primary use case on external pentests.
You may notice we are using TextFields for all these columns rather than VarChars. That is because in PostgreSQL VarChars are actually stored as TextFields internally, and VarChars actually may be slower due to additional validation checks. https://www.postgresql.org/docs/11/datatype-character.html
You may want different fields to be captured, perhaps an email field and a separate username field, or even metadata like time added or date of the leak. Feel free to modify as you see fit for your needs as you go along, but bear in mind adding columns could have a large storage costs over the massive datasets we will be ingesting.
After defining our model, and having set up the database, we can then run:
python manage.py makemigration
python manage.py migrate
This will create the leaked passwords table in our database and populate it with the defined columns. At this point, no indexes or constraints are present on the Table, which will greatly speed ingestion. It is faster to filter the data in the DB and apply constraints and indexes after ingestion.
Getting some leaks
Before we go about building the ingester, let's make sure we actually have something to ingest! The best advice I can give for hunting down leaks is to practice your google fu, but the following Torrents are a great foundation for a database, containing AntiPublic and BreachCompiliation, two massive compilations of leaked passwords.
BreachCompilation:
magnet:?xt=urn:btih:7ffbcd8cee06aba2ce6561688cf68ce2addca0a3&dn=BreachCompilation&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a80&tr=udp%3a%2f%2ftracker.leechers-paradise.org%3a6969&tr=udp%3a%2f%2ftracker.coppersurfer.tk%3a6969&tr=udp%3a%2f%2fglotorrents.pw%3a6969&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337
Collection 1:
magnet:?xt=urn:btih:b39c603c7e18db8262067c5926e7d5ea5d20e12e&dn=Collection%201&tr=udp%3a%2f%2ftracker.coppersurfer.tk%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.leechers-paradise.org%3a6969%2fannounce&tr=http%3a%2f%2ft.nyaatracker.com%3a80%2fannounce&tr=http%3a%2f%2fopentracker.xyz%3a80%2fannounce
Collection 1-5 + AntiPublic
magnet:?xt=urn:btih:d136b1adde531f38311fbf43fb96fc26df1a34cd&dn=Collection%20%232-%235%20%26%20Antipublic&tr=udp%3a%2f%2ftracker.coppersurfer.tk%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.leechers-paradise.org%3a6969%2fannounce&tr=http%3a%2f%2ft.nyaatracker.com%3a80%2fannounce&tr=http%3a%2f%2fopentracker.xyz%3a80%2fannounce
Optionally, after downloading the data, you can leverage GNU tools like sort, cut, grep, etc to clean and organize the data. We experimented with this, sorting and uniqing a number of the lists with sort -u, but ultimately concluded that many of these sorting operations are much faster in PostgreSQL. You are likely much better off ingesting the raw data, and then organizing and uniqing later in Postgres. Of course, use what you feel most comfortable with.
Ingestion Script
With our list of leaked emails and passwords in hand, the next step is to ingest them into the database. There a number of ways to approach this, but we opted to use Django's ORM for the ingestion. This could be further optimized with direct SQL queries, but was fast enough for our needs while being easily readable and maintainable.
import sys, os
import gc
from contextlib import closing
sys.path.append('<path to your django app>')
os.environ['DJANGO_SETTINGS_MODULE'] = 'settings'
import django
django.setup()
from django.db import close_old_connections
from django import db
from django.db import connection
from password_reaper.models import LeakedCredential
import argparse
ALLOWED_DOMAINS = [".gov", '.us', '.com', '.org', '.net', '.biz']
def load_passwords_from_file(f, skips):
source = os.path.basename(f)
BATCH_SIZE = 1000000
with open(f,'r', errors='replace') as passfile:
batch = []
##skips
REPORT_INTERVAL = BATCH_SIZE
current_skip = 0
for _ in range(skips):
current_skip += 1
if current_skip % REPORT_INTERVAL == 0:
print("skipped: " + str(current_skip))
next(passfile)
print("closing old connections")
close_old_connections()
print("preparing first batch...")
ru_skips =0
for userpass in passfile:
current_skip += 1
try:
if len(userpass) > 500:
continue
if(":" in userpass):
userpassarray = userpass.replace('\x00','').split(':',1)
elif(';' in userpass):
userpassarray = userpass.replace('\x00','').split(';',1)
else:
continue
username = userpassarray[0].lower()
if "@" in username:
domain = username.split('@')[1].lower()
good_domain = any(n in domain for n in ALLOWED_DOMAINS)
if not good_domain:
ru_skips +=1
continue
#if not domain.endswith('.com'):
# ru_skips +=1
# continue
else:
domain = None;
password =userpassarray[1].rstrip('\n')
except:
print("we hit an exception for " + str(userpass))
continue
batch.append(LeakedCredential(username=username,domain=domain, password=password,source=source))
if len(batch) >= BATCH_SIZE:
print(" submitting batch, last username: " + username)
LeakedCredential.objects.bulk_create(batch, ignore_conflicts=True)
print("batched on username: " + username)
print("skipped ru domains: " + str(ru_skips))
ru_skips = 0
print("deleting cache list")
del batch
batch = []
#print("current db count:" + str(LeakedCredential.objects.count()))
print("current file line position:" + str(current_skip))
#print("current file seek position:" + str(passfile.tell()))
print("resetting queries")
db.reset_queries()
print("preparing next batch...")
#catch that final batch
if len(batch) > 0:
print(" submitting final, last username: " + username)
print("current file line position:" + str(current_skip))
LeakedCredential.objects.bulk_create(batch, ignore_conflicts=True)
print("done")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='load in that file')
parser.add_argument('-f',metavar='input file' ,help='file with le passwords', required=False)
parser.add_argument('-s',metavar='input file' ,help='skiplines', required=False)
args = parser.parse_args()
#print("getting DB Count...")
#print(LeakedCredential.objects.count())
if args.s:
skips = int(args.s)
else:
skips =0
if args.f:
load_passwords_from_file(args.f, skips)
This script will bootstrap itself into a Django environment (be sure to point that at the right place!) and load in the passwords with Django's ORM.
We are expecting the format of the file being loaded to be email:pass, but this can be modified to ingest files of various formats or with hashes, etc.
In our case, we also opted to skip any domains that don't match our whitelist to save space, because we largely do not care about .ru or .cn sites for example. You may want to tweak this to better match your targets, or remove the filter altogether if preferred.
We load in the passwords with batch sizes of 1 million, but feel free to adjust and play around with. We found 1 mil to work well.
Loading them in
here is an example of us loading in a dehashed email:pass format txt file of the Disqus leak. As you can see the script will print out the fileline position of the start of each batch, so that if it fails out, you can resume with the skip lines argument
python reaper/password_reaper/load_passwords.py -f ./disqus_emailpass.txt
/home/kdick/reaper/venv/lib/python3.7/site-packages/requests/__init__.py:91: RequestsDependencyWarning: urllib3 (1.25.3) or chardet (3.0.4) doesn't match a
supported version!
RequestsDependencyWarning)
/home/kdick/reaper/venv/lib/python3.7/site-packages/psycopg2/__init__.py:144: UserWarning: The psycopg2 wheel package will be renamed from release 2.8; in order to keep installing from binary please use "pip install psycopg2-binary" instead. For details see: <http://initd.org/psycopg/docs/install.html#binary-install-from-pypi>.
""")
closing old connections
preparing first batch...
submitting batch, last username: chinmay.mesaria@gmail.com
batched on username: chinmay.mesaria@gmail.com
skipped ru domains: 154568
deleting cache list
current file line position:1154568
resetting queries
preparing next batch...
submitting batch, last username: gamespot.ninjasam@yahoo.com
You can even also a quick for loop to load in all files in a given directory if looking to load in a folder with many text lists. The example below will do so for your current directory:
for i in *; do echo "loading $i"; python ~/reaper/password_reaper/load_passwords.py -f "$i"; done
Some of these loads will take hours, particularly breach compilation, maybe faster if you have some nice hardware. Once you are happy with your initial load, we can dudup and add indexes. Loads will still be possible after this, but will be significantly lower as the database will have to check unique constraints and update the relevant indexes while loading. We observed 10-15x slower loads vs no constraints or indices in our testing. The idea is to do this bulk one time load of your current leak collection quickly, and then other leaks can be performed ad hoc at a much slower but still manageable rate.
Deduping and adding unique constraints
Now that we have our data loaded, we can add an index on username/password unique constraint on that index to dedup our data to username/pass combos and keep it de-duplicated on future loads.

Notice this index creation process takes over 3 hours. With the index now in place, we can add the unique constraint using the index, which will dedup the data and enforce future username/password uniqueness.
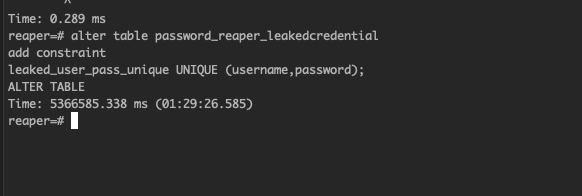
A shorter, but still over an hour long operation.
Adding Search Indexes
Now we can add indexes to support our searching of the database. After some testing and benchmarking we opted to use both btree indexes for equality checks and GIN Trigram indexes (gin_trgm_ops) for partial and regex searches.
BTree Indexes
BTree Indexes are essentially magic, that allow us to search through over 4 billion passwords in milliseconds. These are useful for equality searches and sorting, and we will apply them to the username, password, and domain fields. For our use case, the domain field allows us to use a btree exact search to find all passwords on a domain, useful for when we are targeting a client.
Right off the bat, we actually do not need to create a BTree index for username, as our username, password index already covers that! This index will not work for only searching by password, or by domain field, however so we still add those indexes to the DB.
BTree Index Creation on password, and domain:
CREATE INDEX password_reaper_leakedcredential_password
ON public.password_reaper_leakedcredential
USING btree (password);
CREATE INDEX password_reaper_leakedcredential_domain
ON public.password_reaper_leakedcredential
USING btree (domain);On our system, it took 3 hours to create each index.
Partial and Regex searches, GIST vs GIN Indexes
Equality searches are great, but we also would like to run partial searches against our DB on usernams and/or passwords. Enter pg_trgm, which allows us to create indexes which support ilike and regex matching.
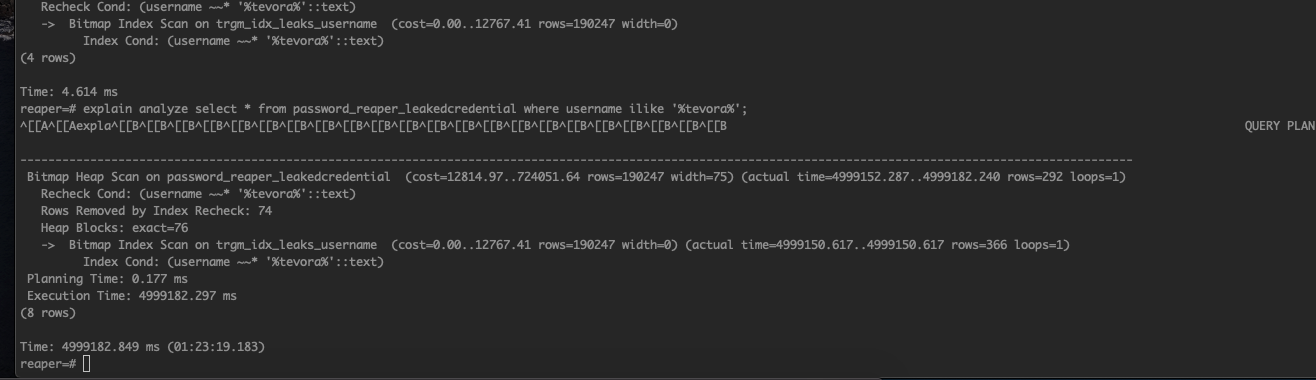
There are two variants of pg_trgm indexes, GIN and GIST. We experimented with search times, data storage, and functionality between GIST and GIN Trigram Indexes, and found GIST to be worse in every aspect. For this use case it used nearly double the data and had over 1000x slower search times. See the timings of our creation and searching below:
GIST Index Size and Search Times (Do not use, bad!)
GIST Trigram Index Creation
CREATE INDEX _trgm_idx_leaks_username
ON password_reaper_leakedcredential
USING gist (username gist_trgm_ops);Resulting Size

Search Time
GIN Index Size and Search Times (Great! use this!)
GIST Trigram Index Creation
CREATE INDEX password_reaper_leaked_credential_trgm_idx_leaks_username
ON password_reaper_leakedcredential
USING gin (username gin_trgm_ops);Resulting Size

Search Time

Notice our GIN index searches in ~50ms vs 1.5 hours, and takes up about 50GB vs over 200GB. Win-win. Postgres experts, weigh in to let me know if this is really how it should be, and when a GIST index would be an appropriate choice if ever.
Building an API to Search the DB
Now that we have the data ingested, indexed, and searchable in our PostgresDB, we can leverage Django Rest Framework to wire up an API to it.
leaked_passwords_api.py
from collections import OrderedDict
from django_filters.rest_framework import DjangoFilterBackend
from rest_framework import viewsets, serializers
from rest_framework.response import Response
from rest_framework.settings import api_settings
from rest_framework.filters import OrderingFilter, SearchFilter
from password_reaper.models import LeakedCredential
from django.db.models.constants import LOOKUP_SEP
from django.utils import six
from django.utils.encoding import force_text
from django.utils.translation import ugettext_lazy as _
from rest_framework.compat import (
coreapi, coreschema, distinct
)
from django.core.paginator import Paginator as DjangoPaginator
from rest_framework.pagination import LimitOffsetPagination
from django.template import loader
from functools import reduce
import operator
from django.db import models
from django.db.models.lookups import IContains
class PostgreILike(IContains):
lookup_name = 'ilike'
def as_postgresql(self, compiler, connection):
lhs, lhs_params = self.process_lhs(compiler, connection)
rhs, rhs_params = self.process_rhs(compiler, connection)
params = lhs_params + rhs_params
return '%s ILIKE %s' % (lhs, rhs), params
models.CharField.register_lookup(PostgreILike)
models.TextField.register_lookup(PostgreILike)
class IlikeSearchFilter(SearchFilter):
def construct_search(self, field_name):
lookup = self.lookup_prefixes.get(field_name[0])
if lookup:
field_name = field_name[1:]
else:
lookup = 'ilike'
return LOOKUP_SEP.join([field_name, lookup])
class QuickNocountPaginator(DjangoPaginator):
def count(self):
"""Return the total number of objects, across all pages."""
return 0
def num_pages(self):
return 0
class LargeResultsSetPagination(LimitOffsetPagination):
default_limit = 1000
def get_paginated_response(self, data):
count = len(data)
if count > self.limit and self.template is not None:
self.display_page_controls = True
return Response(OrderedDict([
('limit', self.limit),
('offset', self.offset),
('returned', count),
('results', data)
]))
#https://stackoverflow.com/questions/31740039/django-rest-framework-pagination-extremely-slow-count
def paginate_queryset(self, queryset, request, view=None):
self.count = 0
self.limit = self.get_limit(request)
if self.limit is None:
return None
self.display_page_controls = True
self.offset = self.get_offset(request)
self.request = request
return list(queryset[self.offset:self.offset + self.limit])
class LeakedPasswordSerializer(serializers.ModelSerializer):
class Meta:
model = LeakedCredential
fields = '__all__'
class LeakedPasswordViewset(viewsets.ModelViewSet):
search_fields = ('username','password')
#filter_fields = ('username', 'source','password','domain')
filter_fields = ('domain','username','password')
ordering_fields = ['username']
filter_backends = (DjangoFilterBackend,IlikeSearchFilter,OrderingFilter)
pagination_class = LargeResultsSetPagination
def get_queryset(self):
queryset = LeakedCredential.objects.all()
return queryset
def get_serializer_class(self):
serializer = LeakedPasswordSerializer
return serializer
In this API python file, we:
- Customize the SearchFilter to use ilike queries which use our trigram index as IlikeSearchFilter
- Customize LimitOffsetPagination to only return the first 1000 rows of any query by default as LargeResultsSetPagination
- Define a ModelSerializer for our LeakedCredential model
- Create a ViewSet with our customized IlikeSearchFilter class, OrderingFilter, and LargeResultsSetPagination classes, referencing the LeakedPasswordsSerializer we made
In order to use this API file you must customize urls.py (see: https://www.django-rest-framework.org/tutorial/6-viewsets-and-routers/) and settings.py (see: https://www.enterprisedb.com/postgres-tutorials/how-use-postgresql-django. )to configure the URL routes to this API and configure your Django settings (such as db, installed apps, etc). We will release a ready to go standalone application with these configurations included as samples once cleaned up a bit, follow us on GitHub to see when that drops.
Once you have everything wired up you should get something like this at your specified url
Click on the filters field to bring in a basic UI for querying the API
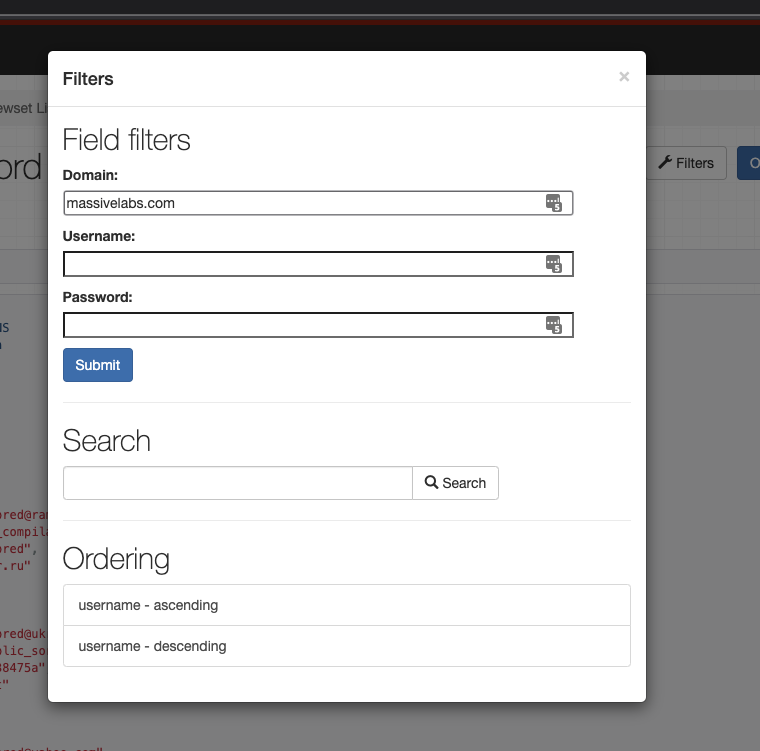
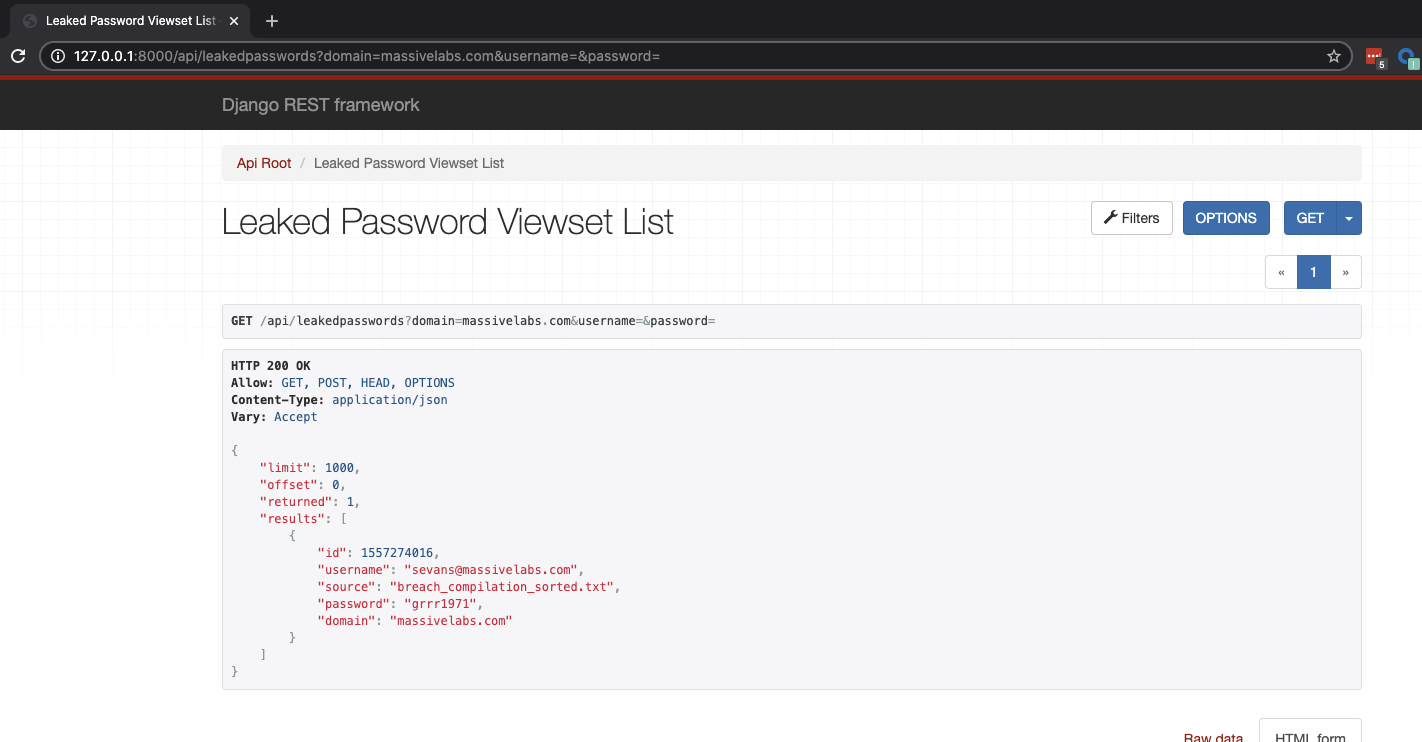
At this point, this API is ready to go for searching and basic CRUD operations. You may be ok stopping here, and just using this for your searching needs. Continue on if you want guidance on building a basic frontend interface ahead of our part 2.
Frontend Application Preview and Closing Thoughts
A frontend interface is useful not only for a slicker presentation, but also for easily adding exports/downloads of data in various formats such as user:pass lists, wordlists, or csv files.
Angular Material
I like to use Angular with the Material Angular library to build nice interfaces with tons of existing components to leverage. Specifically, the mat-table component is great for displaying data with pagination, filtration, sorting, etc all handled.
Table and PasswordService Code
We will be covering how to build this out fully in an upcoming post, but in the meantime for those who are ready to dive in and get it working on your own, here is our table code and password-service code to leverage in your build.
For those familiar with Angular this should be enough to get you most of the way to a working frontend. For those who are still a bit lost, fret not! Stay tuned for a complete working API and Frontend code release, as well as frontend walkthrough, in part 2!
leaked-passwords-table.component.html
<div class="mat-elevation-z8">
<div class="filter-header">
<form class="password-search-form">
<span class="flexy_span">
<mat-form-field class="example-half-width-rpad">
<input matInput placeholder="username (exact match)" [(ngModel)]="username_filter" name="username">
</mat-form-field>
<mat-form-field class="example-half-width-rpad">
<input matInput placeholder="domain (exact match)" [(ngModel)]="domain_filter" name="domain_filter">
</mat-form-field>
<mat-form-field class="example-half-width-rpad">
<input matInput placeholder="Username and Password Search (ilike comparison)" [(ngModel)]="userpass_search" name="userpass_search">
</mat-form-field>
<button mat-button color="primary" (click)="searchPasswords()">Search</button>
</span>
</form>
</div>
<mat-progress-bar *ngIf="loading" mode="buffer"></mat-progress-bar>
<mat-divider></mat-divider>
<div class="filter-header">
<mat-form-field style="width: 100%">
<input matInput (keyup)="applyFilter($event.target.value)" placeholder="Filter">
</mat-form-field>
</div>
<div class="mat-table">
<table mat-table class="full-width-table" [dataSource]="dataSource" matSort aria-label="Elements">
<ng-container matColumnDef="{{column}}" *ngFor="let column of dynamicColumns">
<th mat-header-cell *matHeaderCellDef mat-sort-header> {{column}} </th>
<td mat-cell *matCellDef="let finding"> {{finding[column]}} </td>
</ng-container>
<ng-container matColumnDef="controls" >
<th mat-header-cell *matHeaderCellDef style="width:300px"> Controls</th>
<td mat-cell *matCellDef="let finding">
<a style="margin-left:16px;" mat-raised-button color="primary"
routerLink="/hosts/{{finding.id}}">GoTo</a>
</td>
</ng-container>
<tr mat-header-row *matHeaderRowDef="displayedColumns"></tr>
<tr mat-row *matRowDef="let row; columns: displayedColumns;">
</tr>
</table>
</div>
<mat-paginator #paginator
[length]="dataSource.data.length"
[pageIndex]="0"
[pageSize]="50"
[pageSizeOptions]="[25, 50, 100, 250]">
</mat-paginator>
<button mat-button (click)="downloadCsv()">Export CSV</button>
<button mat-button (click)="downloadUserPass()">Export UserPass</button>
<button mat-button (click)="downloadWordlist()">Export Wordlist</button>
</div>
leaked-passwords-table.component.ts
import {Component, Input, OnInit, ViewChild} from '@angular/core';
import {MatDialog, MatPaginator, MatSort, MatTableDataSource} from '@angular/material';
import {ProjectService} from '../project.service';
import {AngularCsv} from 'angular7-csv';
import {LeakedPasswordService} from '../leaked-password.service';
import {downloadFile} from '../download_tools';
@Component({
selector: 'app-leaked-passwords-table',
templateUrl: './leaked-passwords-table.component.html',
styleUrls: ['./leaked-passwords-table.component.css']
})
export class LeakedPasswordsTableComponent implements OnInit {
@ViewChild(MatPaginator) paginator: MatPaginator;
@ViewChild(MatSort) sort: MatSort;
dataSource: MatTableDataSource<any>;
/** Columns displayed in the table. Columns IDs can be added, removed, or reordered. */
dynamicColumns = ['id', 'username', 'password','domain','source'];
displayedColumns = this.dynamicColumns
public leakedpasswords= [];
public loading = false;
constructor(public dialog:MatDialog, public leakedPasswordService: LeakedPasswordService){}
public renderedData = {};
public username_filter: string = "";
public password_filter: string = "";
public userpass_search: string = "";
public domain_filter: string = ""
public offset= 0;
public limit = 1000;
ngOnInit() {
this.dataSource = new MatTableDataSource(this.leakedpasswords);
this.dataSource.paginator = this.paginator;
this.dataSource.sort = this.sort;
this.dataSource.connect().subscribe(d => this.renderedData = d);
}
downloadCsv(){
const pick = (obj, keys) =>
Object.keys(obj)
.filter(i => keys.includes(i))
.reduce((acc, key) => {
acc[key] = obj[key];
return acc;
}, {})
let options = {
fieldSeparator: ',',
quoteStrings: '"',
decimalseparator: '.',
showLabels: true,
useBom: true,
headers: this.dynamicColumns
};
//console.log(.*);
let leakedpasswords = this.leakedpasswords.map(host => pick(host, this.dynamicColumns));
new AngularCsv(leakedpasswords, `${this.domain_filter}_${this.username_filter}_${this.password_filter}_leakpass`, options);
}
downloadUserPass(){
const pick = (obj, keys) =>
Object.keys(obj)
.filter(i => keys.includes(i))
.reduce((acc, key) => {
acc[key] = obj[key];
return acc;
}, {})
let leakedpasswords = this.leakedpasswords.map(host => pick(host, ["username", "password"]));
let leaked_userpasses= leakedpasswords.map(leakedpassword => leakedpassword["username"] + ':' + leakedpassword["password"] );
let leaked_userpasses_text = leaked_userpasses.join('\n');
downloadFile(leaked_userpasses_text, `${this.domain_filter}_${this.username_filter}_${this.password_filter}_userpass.txt`);
}
downloadWordlist(){
const pick = (obj, keys) =>
Object.keys(obj)
.filter(i => keys.includes(i))
.reduce((acc, key) => {
acc[key] = obj[key];
return acc;
}, {})
let leakedpasswords = this.leakedpasswords.map(host => host["password"]);
let leaked_userpasses_text = leakedpasswords.join('\n');
downloadFile(leaked_userpasses_text, `${this.domain_filter}_${this.username_filter}_${this.password_filter}_wordlist.txt`);
}
searchPasswords(){
this.loading = true;
this.leakedPasswordService.searchPasswords(this.username_filter,this.password_filter, this.domain_filter, this.userpass_search, this.offset, this.limit ).subscribe(data =>
{
this.leakedpasswords = data.results;
this.dataSource.data = this.leakedpasswords
this.loading = false;
}, error => this.leakedPasswordService.displayError(error));
}
applyFilter(filterValue: string) {
this.dataSource.filter = filterValue.trim().toLowerCase();
this.dataSource.paginator.firstPage();
}
}
leaked-password-service.ts
import { Injectable } from '@angular/core';
import {HttpClient} from '@angular/common/http';
import {MatDialog, MatSnackBar} from '@angular/material';
import {ErrorSnackBar} from './finding-not-found-snackbar-component';
import {FriendlySnackbar} from './friendly-message-snackbar-component';
import {UserService} from './user.service';
@Injectable({
providedIn: 'root'
})
export class LeakedPasswordService {
constructor(* -forauth-- public userService: UserService,*/ public http: HttpClient, public dialog: MatDialog, public snackBar: MatSnackBar, ) { }
searchPasswords(username, password,domain, search, offset, limit)
{
return this.http.get<any>(`https://<yourapi>/api/leakedpasswords?domain=${domain}&limit=${limit}&password=${password}&username=${username}&search=${search}&offset=${offset}`,
{
//implement auth if you'd like headers:{'Authorization' : 'Token ' + this.userService.currentUserValue.token},
});
}
displayError(error_msg)
{
console.log(error_msg);
let error = JSON.stringify(error_msg);
this.snackBar.openFromComponent(ErrorSnackBar, {
duration: 10 * 1000,
data: error
});
}
displayFriendlyMessage(message, duration=30*3000)
{
this.snackBar.openFromComponent(FriendlySnackbar, {
duration: duration,
data: JSON.stringify(message),
verticalPosition: 'top',
horizontalPosition: 'right'
});
}
}
Closing Thoughts
I hope this gets you started on your own journey and excited about just how powerful PostgreSQL is. Even with searching 4 billion passwords, we are only scratching the surface on what could be built. Leave a comment below with your own ideas, questions, or share some nice leaks ;)!